One Intelligence Loop - Every Use Case, Every Domain
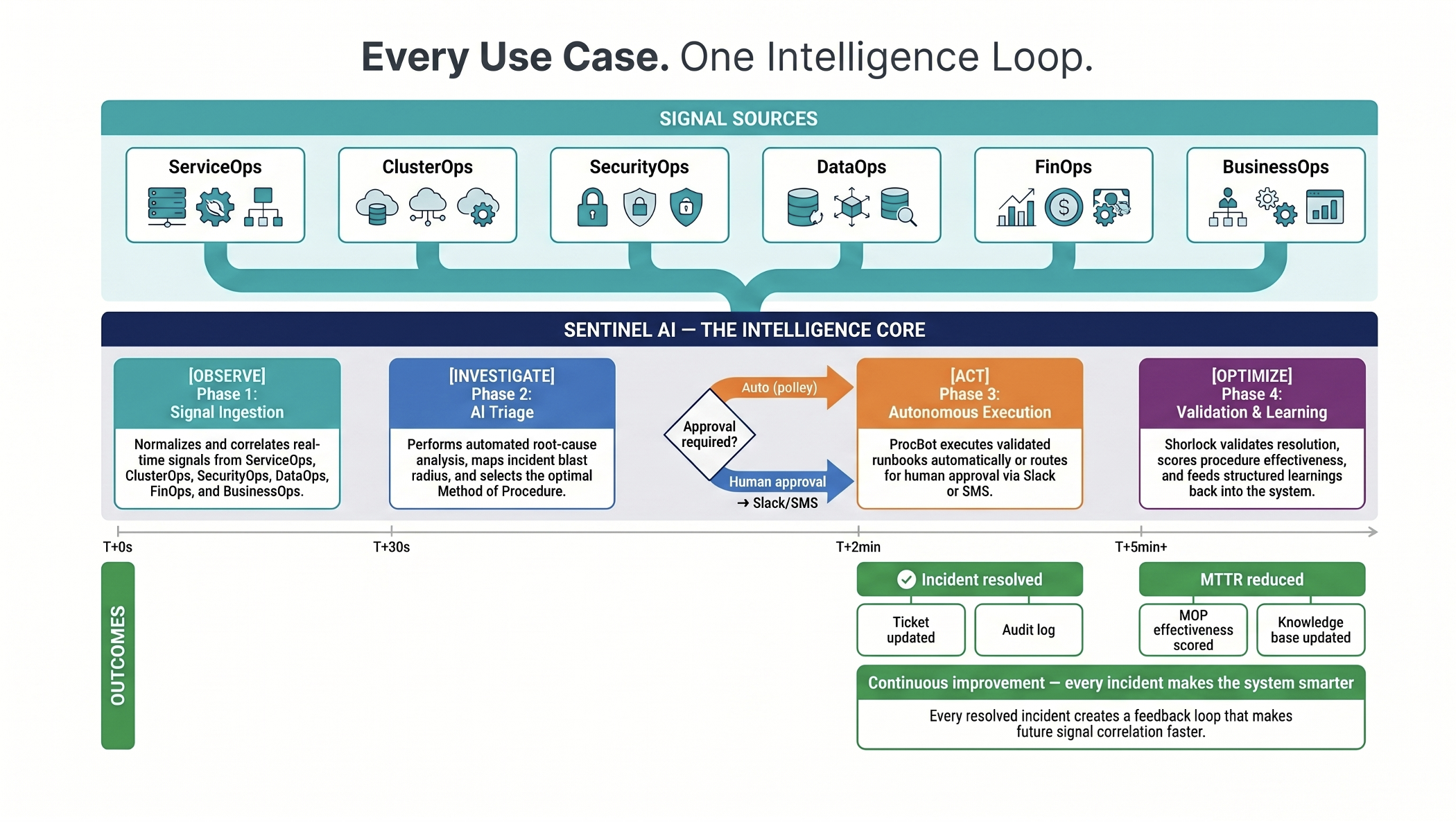
Every use case on this page follows the same closed-loop intelligence cycle - signal detection through to validated resolution and continuous improvement.
Every use case here is drawn from real enterprise ops patterns - sourced from industry research, validated against production environments, and designed to demonstrate measurable, defensible ROI.
Every use case on this page follows the same closed-loop intelligence cycle - signal detection through to validated resolution and continuous improvement.
Every number here is grounded in industry data. No made-up benchmarks - sourced from IBM, Verizon, Gartner, observability platform, CrowdStrike, Sectigo, and Ponemon.
| Use Case | Domain | Time to Resolve | Automation | Primary Benefit |
|---|---|---|---|---|
| UC-01 CPU Spike RCA | Infrastructure | < 4 minutes | Fully Auto | ↓ 70% MTTR |
| UC-02 Latency Topology | Infrastructure | 6 minutes | Fully Auto | ↓ 65% cross-service MTTR |
| UC-03 Disk Space Cleanup | Infrastructure | 18 days early detection | Predictive Auto | ↓ 100% disk-fill outages |
| UC-04 RBAC Misconfiguration | Security | < 2 minutes | Fully Auto | ↓ 80% audit prep time |
| UC-05 Login Investigation | Security | 8 minutes | Fully Auto | ↓ 92% investigation time |
| UC-06 Privilege Escalation | Security | < 90 seconds | Fully Auto | ↓ 85% insider threat response time |
| UC-07 Business Process RCA | Business | 5 minutes | Auto + Notify | ↓ 80% finance team impact |
| UC-08 Helm Rollback | IT Support | 90 seconds | Zero-touch | ↓ 95% deploy incident MTTR |
| UC-09 Unusual Login - Voice Call | Proactive Voice | < 30 seconds | Voice-Verified | ↓ 95% breach risk |
| UC-10 SSH Brute Force - Call | Proactive Voice | < 2 minutes | Voice-Confirmed | ↓ 90% lateral movement risk |
| UC-11 Priv Escalation - Chat | Proactive Chat | < 90 seconds | Chat-Approved | ↓ 85% insider response time |
| UC-12 SSL Certificate Renewal | L1 Automation | 30-day advance action | Fully Auto | ↓ 100% cert-expiry outages |
| UC-13 DB Connection Pool | L1 Automation | 5 minutes | Fully Auto | ↓ 99% cascade failure risk |
| UC-14 User Access Review | L1 Automation | 3 weeks → 2 days | 90% Automated | ↓ 93% manual review effort |
No pre-built demos. We connect to your actual ops stack and show you how Sentinel handles your real incidents.